データ取得とストリーミングの方法
このページでは、サーバーコンポーネントとクライアントコンポーネントでデータを取得する方法と、データに依存するコンポーネントをストリーミングする方法について説明します。
データの取得
サーバーコンポーネント
サーバーコンポーネントでは以下の方法でデータを取得できます:
fetchAPI を使用する- ORM またはデータベース を使用する
fetch API を使用
fetch API でデータを取得するには、コンポーネントを非同期関数に変更し、fetch 呼び出しを待機します。例:
export default async function Page() {
const data = await fetch('https://api.vercel.app/blog')
const posts = await data.json()
return (
<ul>
{posts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}export default async function Page() {
const data = await fetch('https://api.vercel.app/blog')
const posts = await data.json()
return (
<ul>
{posts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}知っておくと良いこと:
fetchのレスポンスはデフォルトでキャッシュされません。ただし、Next.js はルートをプリレンダリングし、パフォーマンス向上のために出力をキャッシュします。動的レンダリングを有効にするには、{ cache: 'no-store' }オプションを使用してください。fetchAPIリファレンスを参照。- 開発中は、
fetch呼び出しをログに記録して可視性とデバッグを向上できます。loggingAPIリファレンスを参照。
ORM またはデータベースを使用
サーバーコンポーネントはサーバーでレンダリングされるため、ORM やデータベースクライアントを使用して安全にデータベースクエリを実行できます。コンポーネントを非同期関数に変更し、呼び出しを待機します:
import { db, posts } from '@/lib/db'
export default async function Page() {
const allPosts = await db.select().from(posts)
return (
<ul>
{allPosts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}import { db, posts } from '@/lib/db'
export default async function Page() {
const allPosts = await db.select().from(posts)
return (
<ul>
{allPosts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}クライアントコンポーネント
クライアントコンポーネントでは以下の2つの方法でデータを取得できます:
- React の
useフック を使用する - SWR や React Query などのコミュニティライブラリを使用する
use フックでデータをストリーミング
React の use フック を使用して、サーバーからクライアントへデータをストリーミングできます。まずサーバーコンポーネントでデータを取得し、Promise をクライアントコンポーネントに props として渡します:
import Posts from '@/app/ui/posts
import { Suspense } from 'react'
export default function Page() {
// データ取得関数を await しない
const posts = getPosts()
return (
<Suspense fallback={<div>Loading...</div>}>
<Posts posts={posts} />
</Suspense>
)
}import Posts from '@/app/ui/posts
import { Suspense } from 'react'
export default function Page() {
// データ取得関数を await しない
const posts = getPosts()
return (
<Suspense fallback={<div>Loading...</div>}>
<Posts posts={posts} />
</Suspense>
)
}次に、クライアントコンポーネントで use フックを使用して Promise を読み取ります:
'use client'
import { use } from 'react'
export default function Posts({
posts,
}: {
posts: Promise<{ id: string; title: string }[]>
}) {
const allPosts = use(posts)
return (
<ul>
{allPosts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}'use client'
import { use } from 'react'
export default function Posts({ posts }) {
const posts = use(posts)
return (
<ul>
{posts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}上記の例では、<Posts> コンポーネントは <Suspense> 境界でラップされています。これは Promise が解決される間、フォールバックが表示されることを意味します。ストリーミングについて詳しく学びます。
コミュニティライブラリ
SWR や React Query などのコミュニティライブラリを使用して、クライアントコンポーネントでデータを取得できます。これらのライブラリには、キャッシュ、ストリーミングなどの独自のセマンティクスがあります。例えば、SWR を使用する場合:
'use client'
import useSWR from 'swr'
const fetcher = (url) => fetch(url).then((r) => r.json())
export default function BlogPage() {
const { data, error, isLoading } = useSWR(
'https://api.vercel.app/blog',
fetcher
)
if (isLoading) return <div>Loading...</div>
if (error) return <div>Error: {error.message}</div>
return (
<ul>
{data.map((post: { id: string; title: string }) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}'use client'
import useSWR from 'swr'
const fetcher = (url) => fetch(url).then((r) => r.json())
export default function BlogPage() {
const { data, error, isLoading } = useSWR(
'https://api.vercel.app/blog',
fetcher
)
if (isLoading) return <div>Loading...</div>
if (error) return <div>Error: {error.message}</div>
return (
<ul>
{data.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}React.cache でリクエストを重複排除
重複排除とは、レンダリングパス中に同じリソースに対する重複リクエストを防ぐプロセスです。これにより、異なるコンポーネントで同じデータを取得しながら、データソースへの複数のネットワークリクエストを防げます。
fetch を使用している場合、cache: 'force-cache' を追加することでリクエストを重複排除できます。これは同じURLとオプションで安全に呼び出せ、1つのリクエストのみが実行されることを意味します。
fetch を使用せず、代わりにORMやデータベースを直接使用する場合は、データ取得を React cache 関数でラップできます。
import { cache } from 'react'
import { db, posts, eq } from '@/lib/db'
export const getPost = cache(async (id: string) => {
const post = await db.query.posts.findFirst({
where: eq(posts.id, parseInt(id)),
})
})import { cache } from 'react'
import { db, posts, eq } from '@/lib/db'
import { notFound } from 'next/navigation'
export const getPost = cache(async (id) => {
const post = await db.query.posts.findFirst({
where: eq(posts.id, parseInt(id)),
})
})ストリーミング
警告: 以下の内容は、アプリケーションで
dynamicIO設定オプション が有効になっていることを前提としています。このフラグは Next.js 15 canary で導入されました。
サーバーコンポーネントで async/await を使用すると、Next.js は動的レンダリングを選択します。これはデータがサーバーで取得され、ユーザーリクエストごとにレンダリングされることを意味します。遅いデータリクエストがある場合、ルート全体のレンダリングがブロックされます。
初期ロード時間とユーザーエクスペリエンスを向上させるために、ストリーミングを使用してページのHTMLを小さなチャンクに分割し、それらのチャンクをサーバーからクライアントに段階的に送信できます。
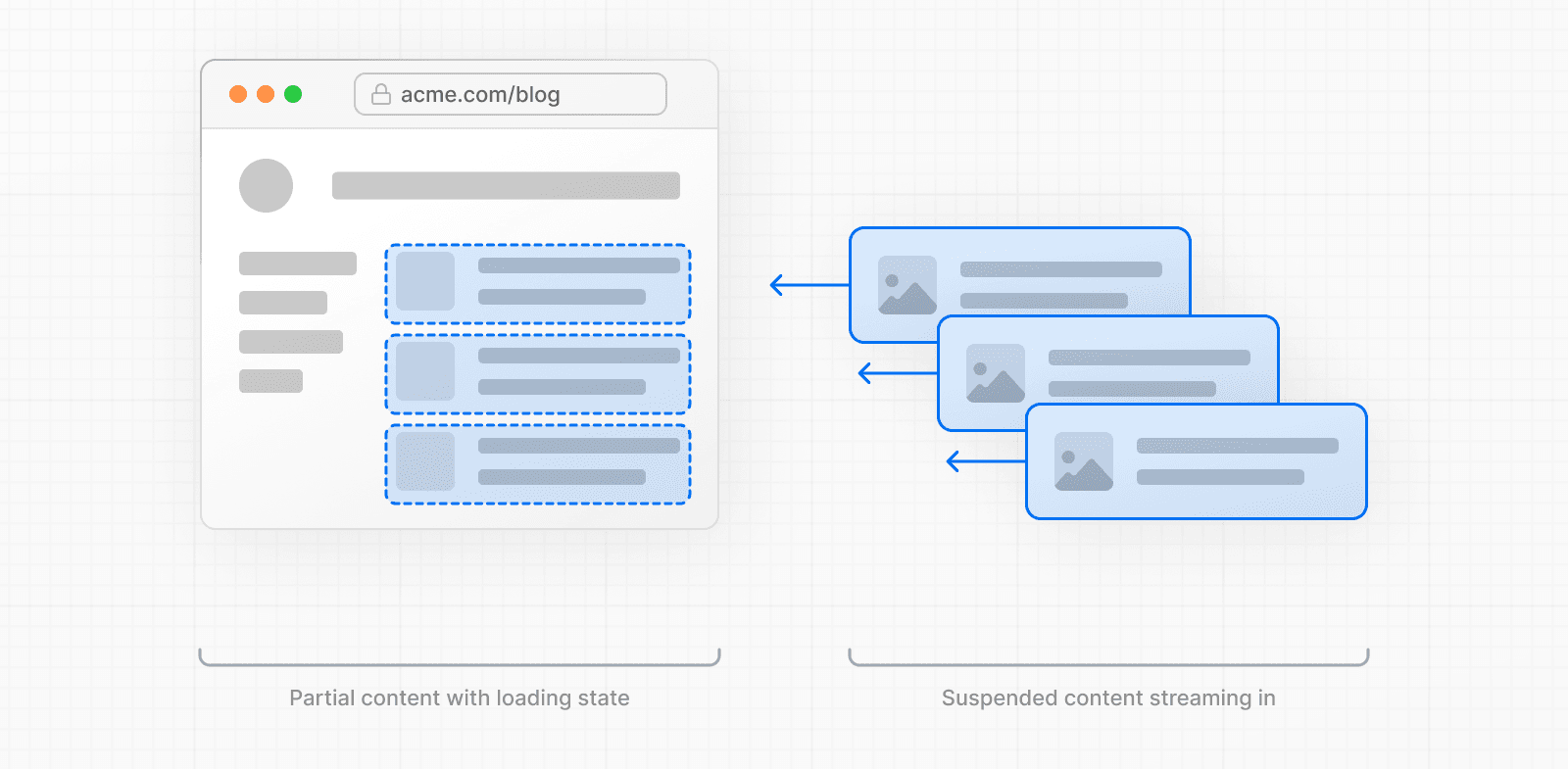
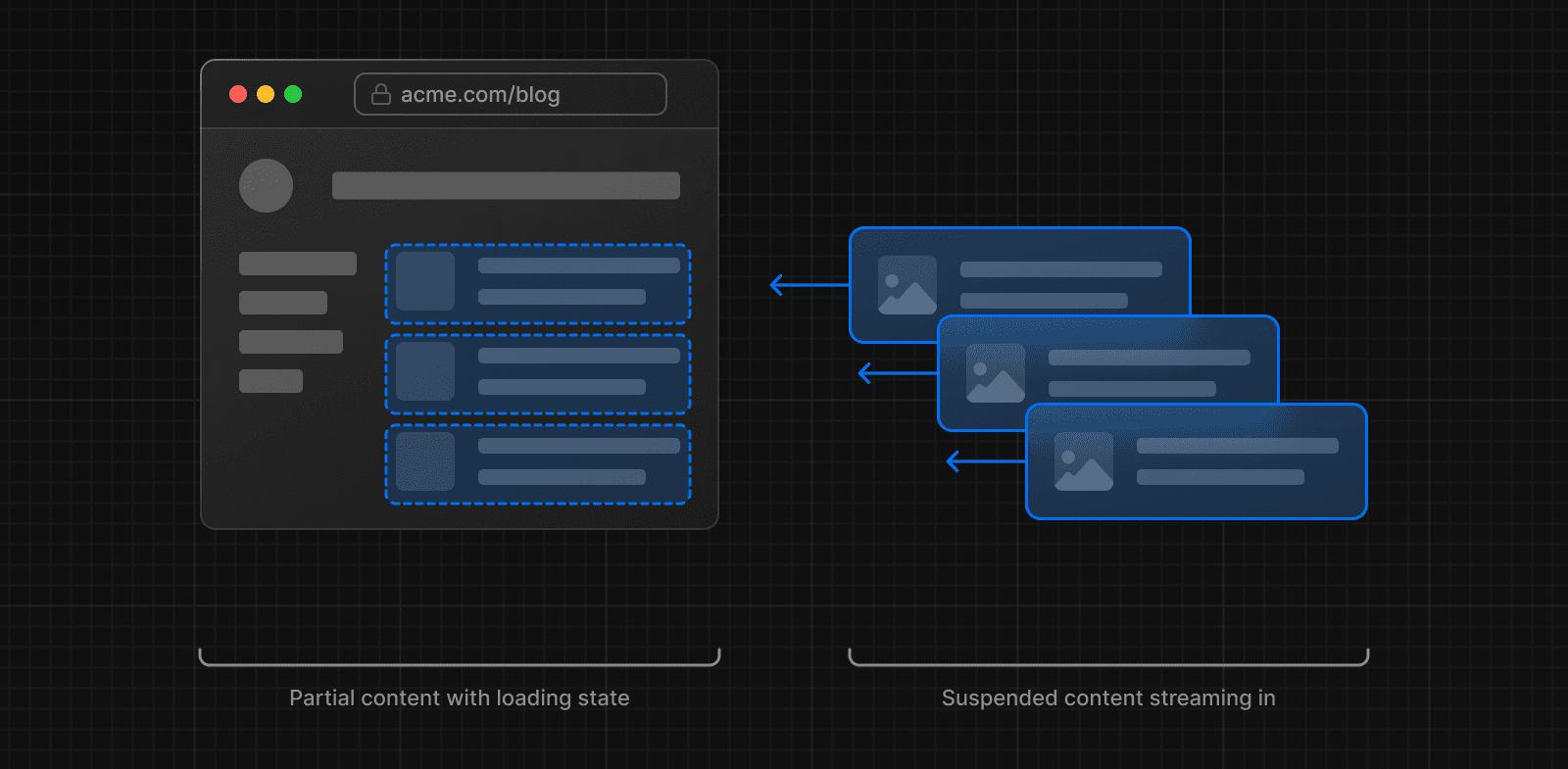
アプリケーションでストリーミングを実装する方法は2つあります:
- ページを
loading.jsファイル でラップする - コンポーネントを
<Suspense>でラップする
loading.js を使用
データ取得中にページ全体をストリーミングするには、ページと同じフォルダに loading.js ファイルを作成します。例えば、app/blog/page.js をストリーミングするには、app/blog フォルダ内にファイルを追加します。
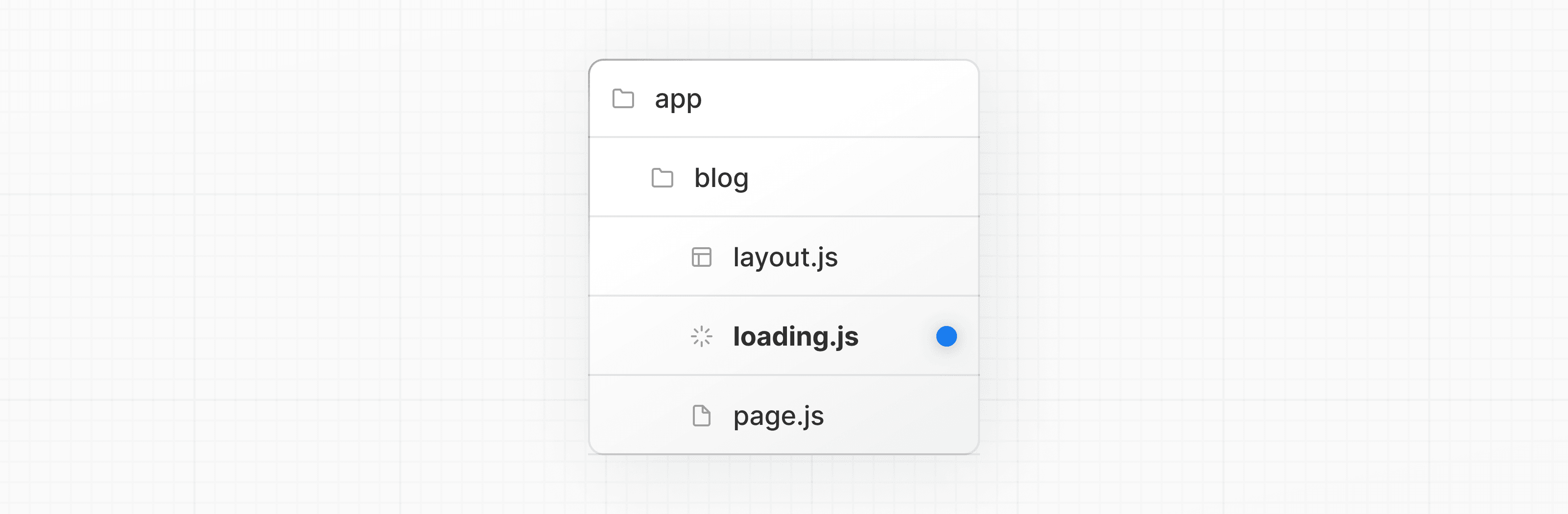
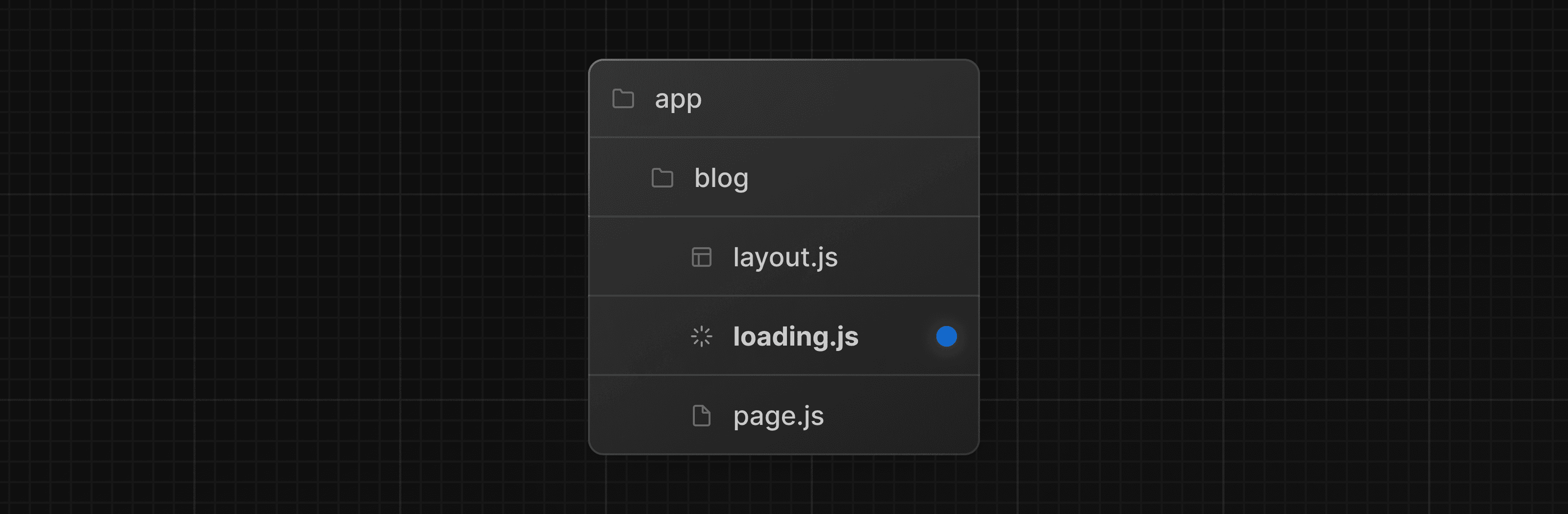
export default function Loading() {
// ローディングUIをここで定義
return <div>Loading...</div>
}export default function Loading() {
// ローディングUIをここで定義
return <div>Loading...</div>
}ナビゲーション時、ユーザーはレイアウトとローディング状態を即座に確認でき、レンダリングが完了すると新しいコンテンツが自動的に切り替わります。
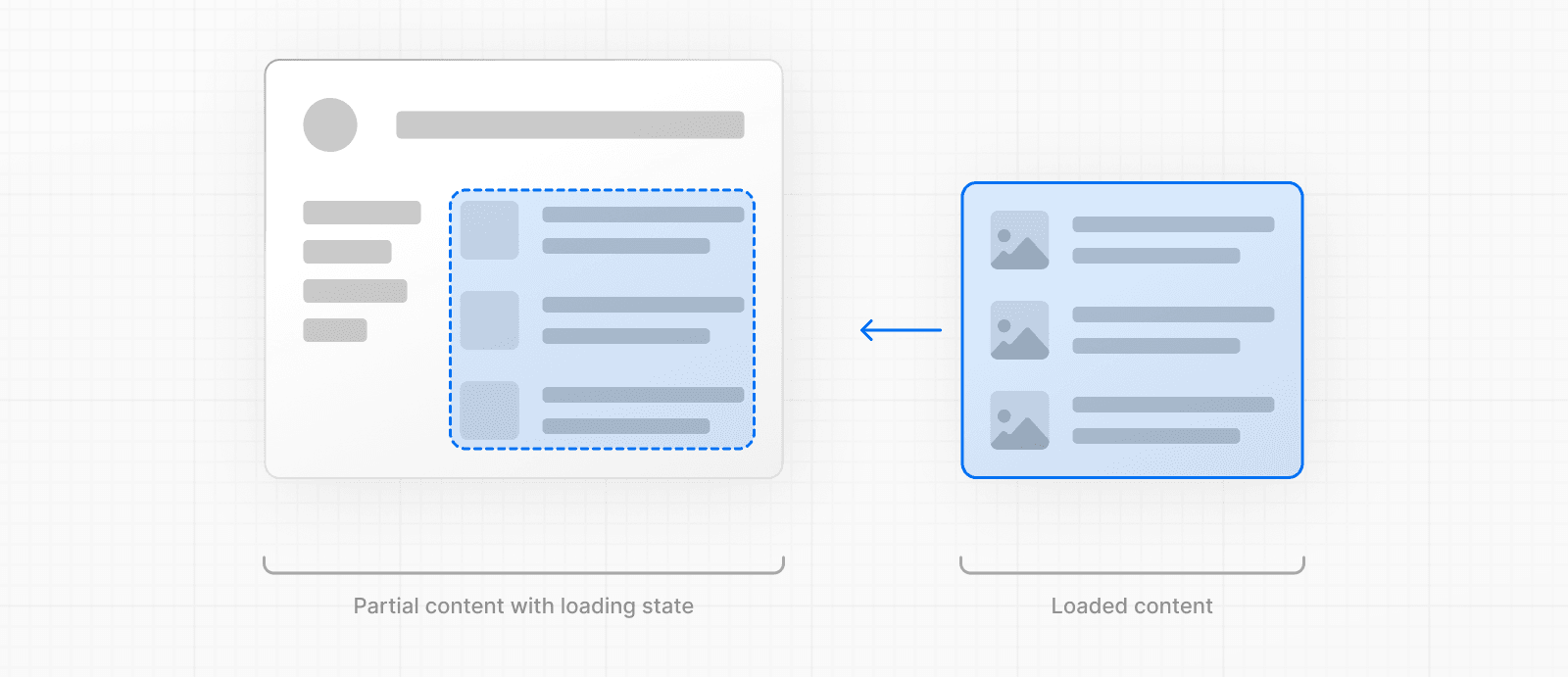
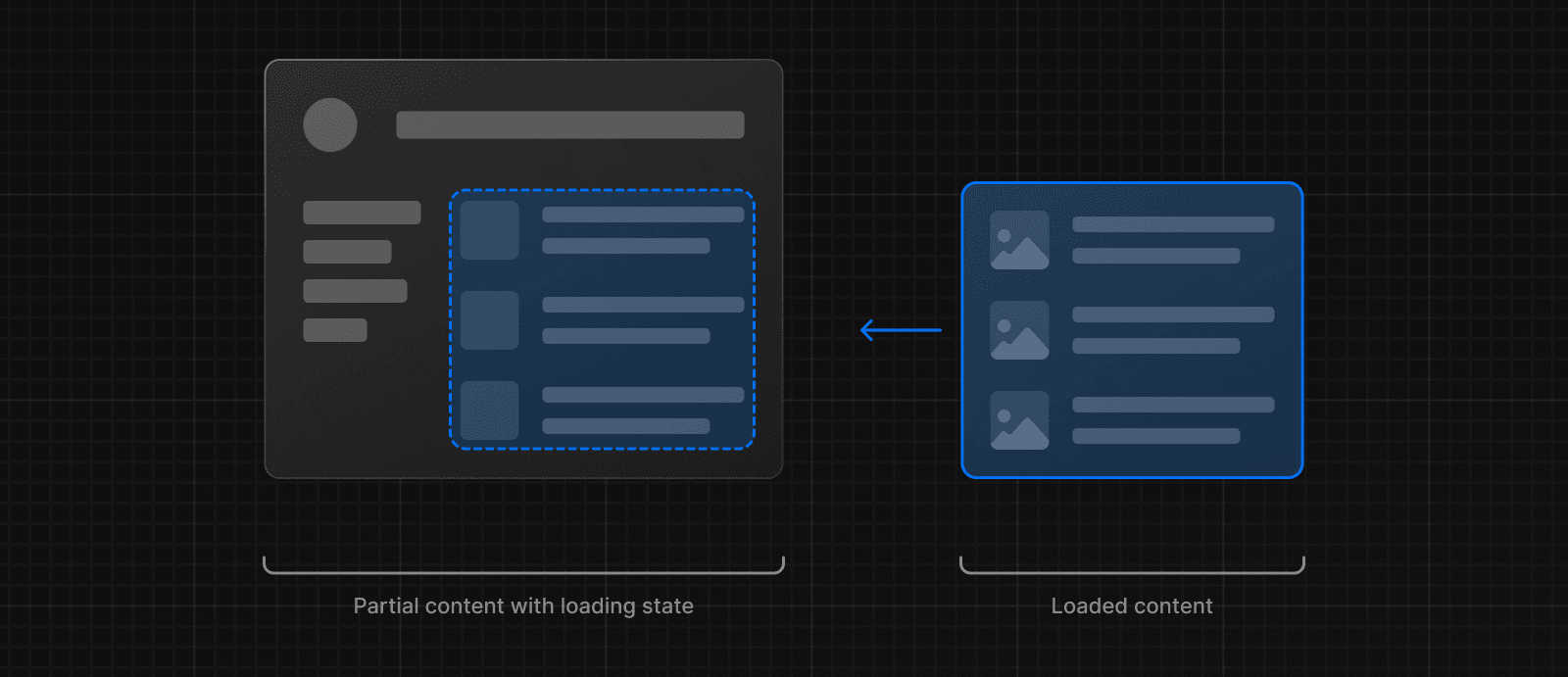
内部的には、loading.js は layout.js 内にネストされ、page.js ファイルとその子を自動的に <Suspense> 境界でラップします。
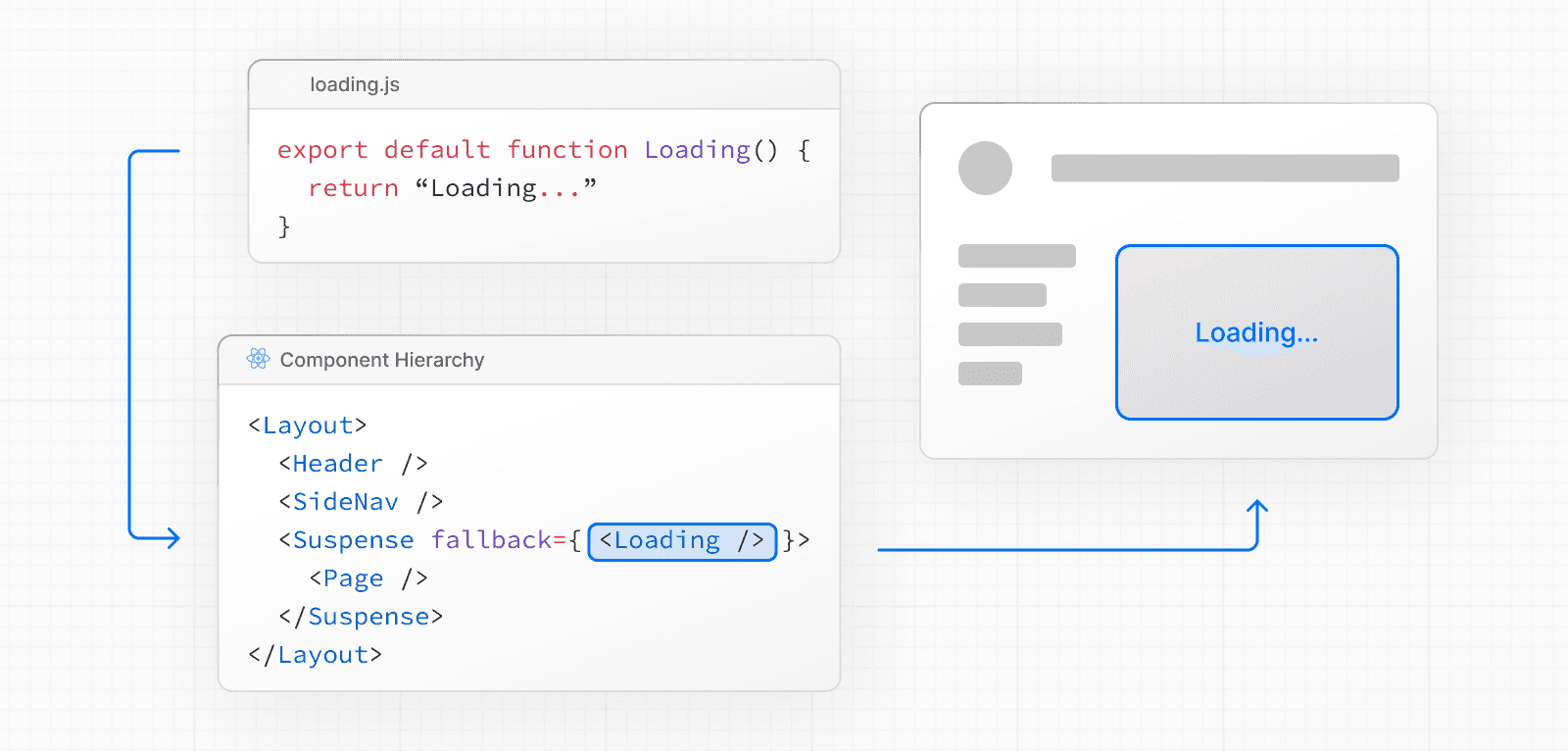
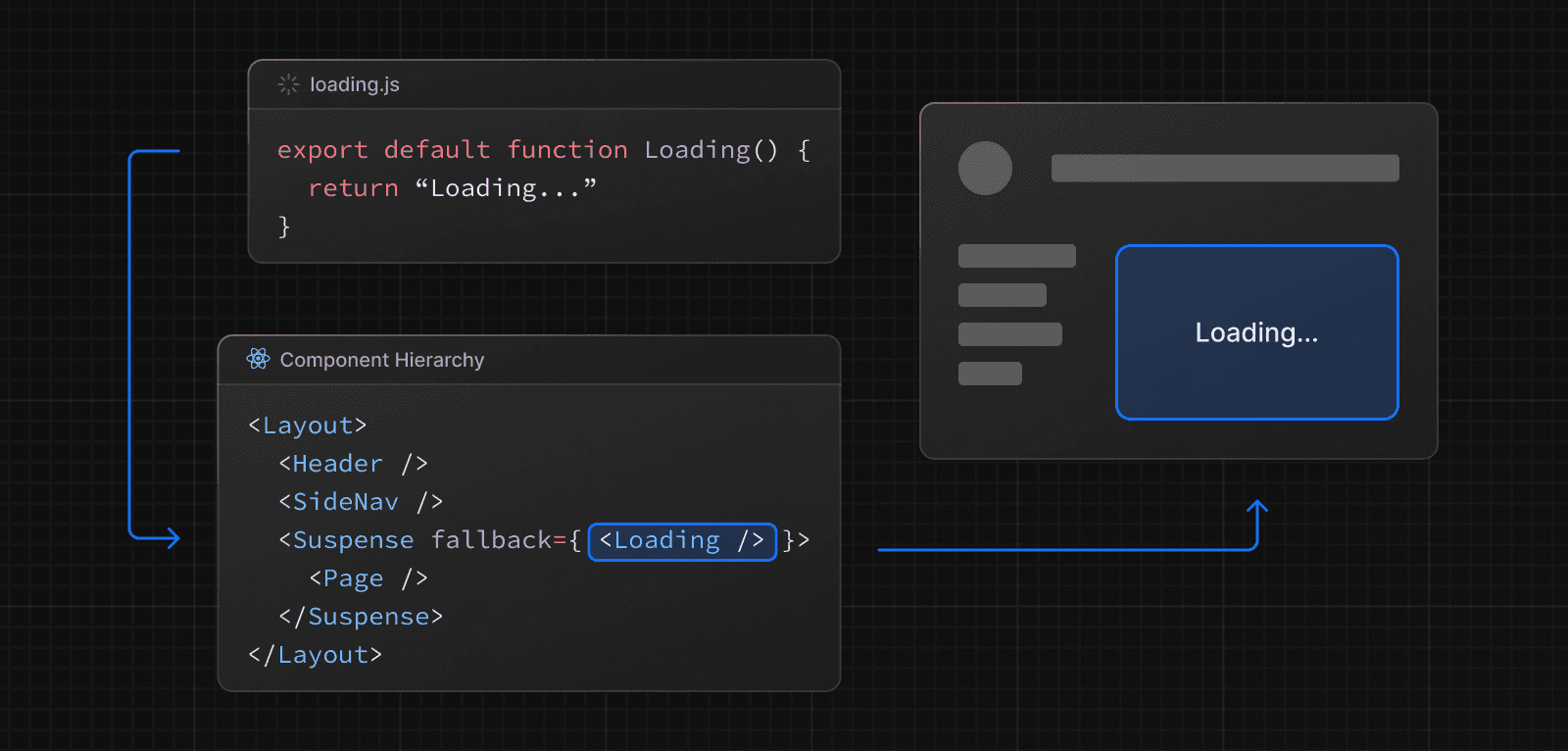
このアプローチはルートセグメント(レイアウトとページ)に適していますが、より細かいストリーミングには <Suspense> を使用できます。
<Suspense> を使用
<Suspense> を使用すると、ページのどの部分をストリーミングするかをより細かく制御できます。例えば、<Suspense> 境界外のページコンテンツを即座に表示し、境界内のブログ投稿リストをストリーミングできます。
import { Suspense } from 'react'
import BlogList from '@/components/BlogList'
import BlogListSkeleton from '@/components/BlogListSkeleton'
export default function BlogPage() {
return (
<div>
{/* このコンテンツは即座にクライアントに送信される */}
<header>
<h1>ブログへようこそ</h1>
<p>最新の投稿を以下で読めます。</p>
</header>
<main>
{/* <Suspense> 境界でラップされたコンテンツはストリーミングされる */}
<Suspense fallback={<BlogListSkeleton />}>
<BlogList />
</Suspense>
</main>
</div>
)
}import { Suspense } from 'react'
import BlogList from '@/components/BlogList'
import BlogListSkeleton from '@/components/BlogListSkeleton'
export default function BlogPage() {
return (
<div>
{/* このコンテンツは即座にクライアントに送信される */}
<header>
<h1>ブログへようこそ</h1>
<p>最新の投稿を以下で読めます。</p>
</header>
<main>
{/* <Suspense> 境界でラップされたコンテンツはストリーミングされる */}
<Suspense fallback={<BlogListSkeleton />}>
<BlogList />
</Suspense>
</main>
</div>
)
}意味のあるローディング状態の作成
インスタントローディング状態とは、ナビゲーション後にユーザーに即座に表示されるフォールバックUIです。最適なユーザーエクスペリエンスのため、アプリが応答していることをユーザーが理解できる意味のあるローディング状態を設計することを推奨します。例えば、スケルトンやスピナー、将来の画面の小さくても意味のある部分(カバー写真、タイトルなど)を使用できます。
開発中は、React Devtools を使用してコンポーネントのローディング状態をプレビューおよび検査できます。
例
逐次的なデータ取得
逐次的なデータ取得は、ツリー内のネストされたコンポーネントがそれぞれ独自のデータを取得し、リクエストが重複排除されない場合に発生し、応答時間が長くなります。
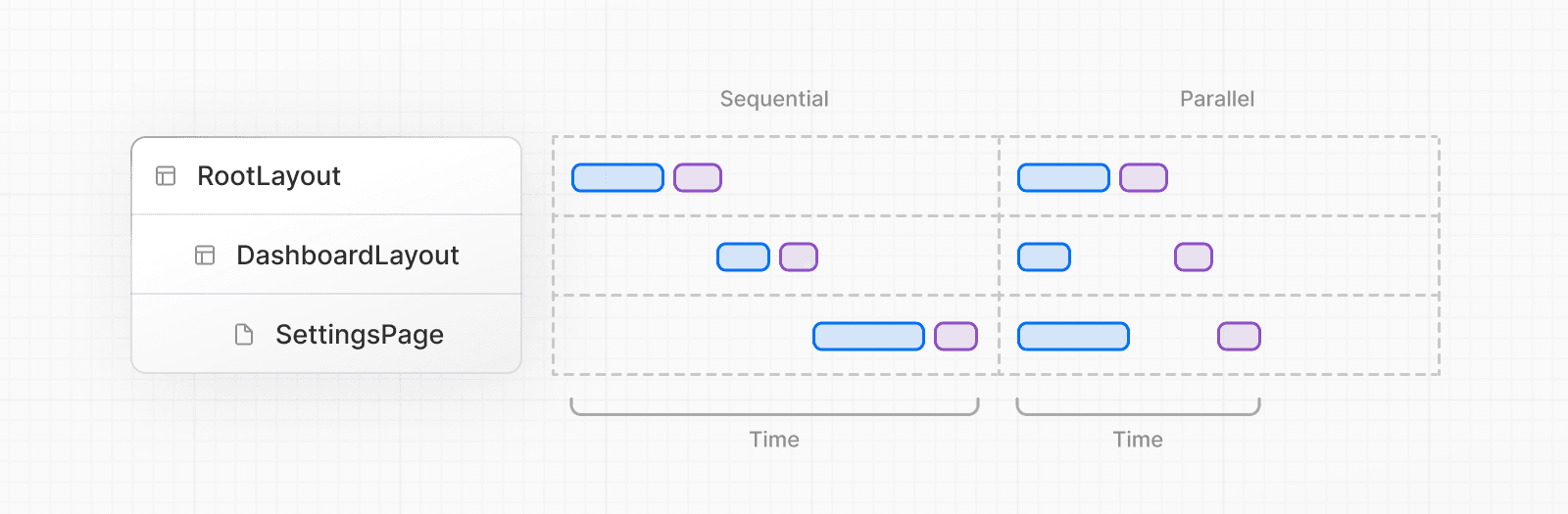
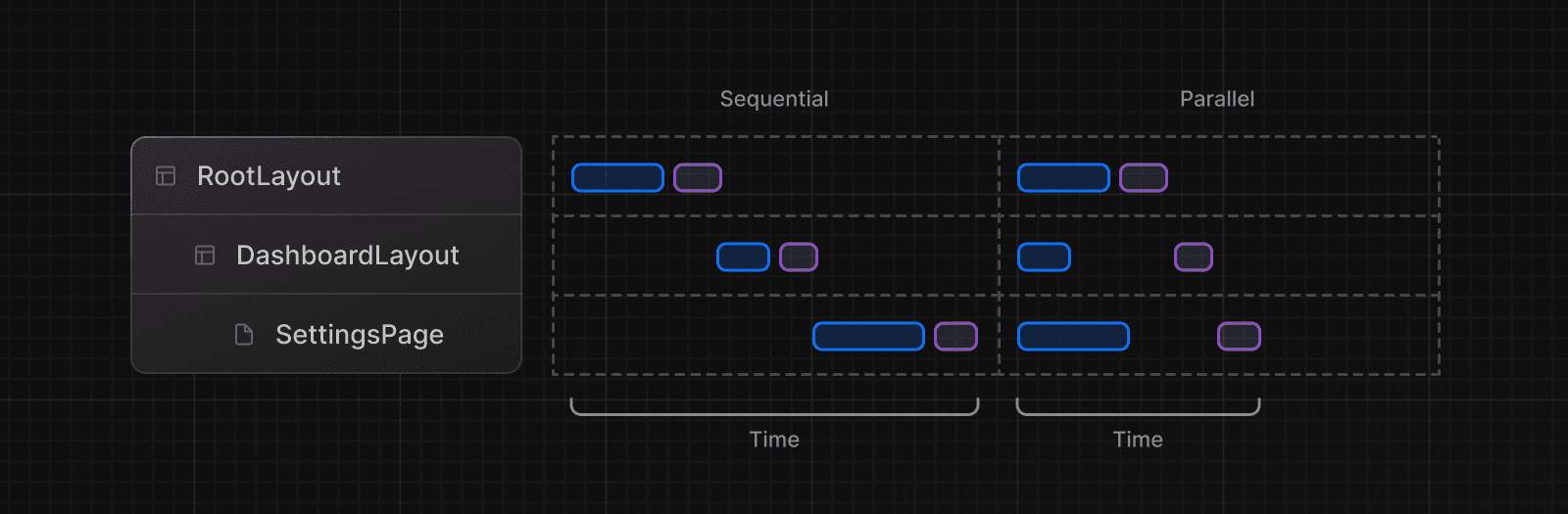
ある取得が他の結果に依存するため、このパターンを意図的に使用する場合があります。
例えば、<Playlists> コンポーネントは <Artist> コンポーネントがデータ取得を終了した後にのみデータ取得を開始します。これは <Playlists> が artistID プロップに依存しているためです:
export default async function Page({
params,
}: {
params: Promise<{ username: string }>
}) {
const { username } = await params
// アーティスト情報を取得
const artist = await getArtist(username)
return (
<>
<h1>{artist.name}</h1>
{/* Playlists コンポーネントのロード中にフォールバックUIを表示 */}
<Suspense fallback={<div>Loading...</div>}>
{/* アーティストIDを Playlists コンポーネントに渡す */}
<Playlists artistID={artist.id} />
</Suspense>
</>
)
}
async function Playlists({ artistID }: { artistID: string }) {
// アーティストIDを使用してプレイリストを取得
const playlists = await getArtistPlaylists(artistID)
return (
<ul>
{playlists.map((playlist) => (
<li key={playlist.id}>{playlist.name}</li>
))}
</ul>
)
}export default async function Page({ params }) {
const { username } = await params
// アーティスト情報を取得
const artist = await getArtist(username)
return (
<>
<h1>{artist.name}</h1>
{/* Playlists コンポーネントのロード中にフォールバックUIを表示 */}
<Suspense fallback={<div>Loading...</div>}>
{/* アーティストIDを Playlists コンポーネントに渡す */}
<Playlists artistID={artist.id} />
</Suspense>
</>
)
}
async function Playlists({ artistID }) {
// アーティストIDを使用してプレイリストを取得
const playlists = await getArtistPlaylists(artistID)
return (
<ul>
{playlists.map((playlist) => (
<li key={playlist.id}>{playlist.name}</li>
))}
</ul>
)
}ユーザーエクスペリエンスを向上させるには、React <Suspense> を使用してデータ取得中に fallback を表示します。これによりストリーミングが有効になり、逐次的なデータリクエストによるルート全体のブロックを防げます。
並列データ取得 (Parallel data fetching)
並列データ取得とは、ルート内のデータリクエストが積極的に開始され、同時に実行されることを指します。
デフォルトでは、レイアウトとページは並列にレンダリングされます。そのため、各セグメントは可能な限り早くデータの取得を開始します。
ただし、任意の コンポーネント内では、複数の async/await リクエストが連続して配置されている場合、それらは順次実行されます。例えば、以下の例では getAlbums は getArtist が解決されるまでブロックされます:
import { getArtist, getAlbums } from '@/app/lib/data'
export default async function Page({ params }) {
// これらのリクエストは順次実行されます
const { username } = await params
const artist = await getArtist(username)
const albums = await getAlbums(username)
return <div>{artist.name}</div>
}データを使用するコンポーネントの外側でリクエストを定義し、Promise.all を使用して一緒に解決することで、リクエストを並列に開始できます:
import Albums from './albums'
async function getArtist(username: string) {
const res = await fetch(`https://api.example.com/artist/${username}`)
return res.json()
}
async function getAlbums(username: string) {
const res = await fetch(`https://api.example.com/artist/${username}/albums`)
return res.json()
}
export default async function Page({
params,
}: {
params: Promise<{ username: string }>
}) {
const { username } = await params
const artistData = getArtist(username)
const albumsData = getAlbums(username)
// 両方のリクエストを並列に開始
const [artist, albums] = await Promise.all([artistData, albumsData])
return (
<>
<h1>{artist.name}</h1>
<Albums list={albums} />
</>
)
}import Albums from './albums'
async function getArtist(username) {
const res = await fetch(`https://api.example.com/artist/${username}`)
return res.json()
}
async function getAlbums(username) {
const res = await fetch(`https://api.example.com/artist/${username}/albums`)
return res.json()
}
export default async function Page({ params }) {
const { username } = await params
const artistData = getArtist(username)
const albumsData = getAlbums(username)
// 両方のリクエストを並列に開始
const [artist, albums] = await Promise.all([artistData, albumsData])
return (
<>
<h1>{artist.name}</h1>
<Albums list={albums} />
</>
)
}補足:
Promise.allを使用する場合、1つのリクエストが失敗すると全体の操作が失敗します。これを回避するには、代わりにPromise.allSettledメソッドを使用できます。
データのプリロード (Preloading data)
ブロッキングリクエストの前に積極的に呼び出すユーティリティ関数を作成することで、データをプリロードできます。以下の例では、<Item> は checkIsAvailable() 関数の結果に基づいて条件付きでレンダリングされます。
checkIsAvailable() の前に preload() を呼び出すことで、<Item/> のデータ依存関係を積極的に開始できます。<Item/> がレンダリングされる時点では、そのデータは既に取得されています。
import { getItem } from '@/lib/data'
export default async function Page({
params,
}: {
params: Promise<{ id: string }>
}) {
const { id } = await params
// アイテムデータの読み込みを開始
preload(id)
// 別の非同期タスクを実行
const isAvailable = await checkIsAvailable()
return isAvailable ? <Item id={id} /> : null
}
export const preload = (id: string) => {
// void は与えられた式を評価し、undefined を返します
// https://developer.mozilla.org/docs/Web/JavaScript/Reference/Operators/void
void getItem(id)
}
export async function Item({ id }: { id: string }) {
const result = await getItem(id)
// ...
}import { getItem } from '@/lib/data'
export default async function Page({ params }) {
const { id } = await params
// アイテムデータの読み込みを開始
preload(id)
// 別の非同期タスクを実行
const isAvailable = await checkIsAvailable()
return isAvailable ? <Item id={id} /> : null
}
export const preload = (id) => {
// void は与えられた式を評価し、undefined を返します
// https://developer.mozilla.org/docs/Web/JavaScript/Reference/Operators/void
void getItem(id)
}
export async function Item({ id }) {
const result = await getItem(id)
// ...さらに、React の cache 関数 と server-only パッケージ を使用して、再利用可能なユーティリティ関数を作成できます。この方法では、データ取得関数をキャッシュし、サーバー上でのみ実行されるようにできます。
import { cache } from 'react'
import 'server-only'
import { getItem } from '@/lib/data'
export const preload = (id: string) => {
void getItem(id)
}
export const getItem = cache(async (id: string) => {
// ...
})import { cache } from 'react'
import 'server-only'
import { getItem } from '@/lib/data'
export const preload = (id) => {
void getItem(id)
}
export const getItem = cache(async (id) => {
// ...
})